Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,[4]这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。
 | |
| 開發者 | Apache软件基金会,領英 |
|---|---|
| 首次发布 | 2011年1月[2] |
| 当前版本 |
|
| 源代码库 | |
| 编程语言 | Scala、Java |
| 操作系统 | 跨平台 |
| 类型 | 流式处理, 消息中间件 |
| 许可协议 | Apache许可证 2.0 |
| 网站 | kafka |
该设计受事务日志的影响较大。[5]
Kafka的历史
Kafka最初是由领英开发,并随后于2011年初开源,并于2012年10月23日由Apache Incubator孵化出站。2014年11月,几个曾在领英为Kafka工作的工程师,创建了名为Confluent的新公司,[6],并着眼于Kafka。根据2014年Quora的帖子,Jay Kreps似乎已经将它以作家弗朗茨·卡夫卡命名。Kreps选择将该系统以一个作家命名是因为,它是“一个用于优化写作的系统”,而且他很喜欢卡夫卡的作品。[7]
Kafka的架构
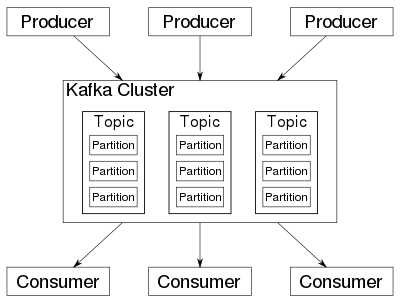
Kafka存储的消息来自任意多被称为“生产者”(Producer)的进程。数据从而可以被分配到不同的“分区”(Partition)、不同的“Topic”下。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为“消费者”(Consumer)的进程可以从分区查询消息。Kafka运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
Kafka高效地处理实时流式数据,可以实现与Storm、HBase和Spark的集成。作为群集部署到多台服务器上,Kafka处理它所有的发布和订阅消息系统使用了四个API,即生产者API、消费者API、Stream API和Connector API。它能够传递大规模流式消息,自带容错功能,已经取代了一些传统消息系统,如JMS、AMQP等。
Kafka架构的主要术语包括Topic、Record和Broker。Topic由Record组成,Record持有不同的信息,而Broker则负责复制消息。Kafka有四个主要API:
- 生产者API:支持应用程序发布Record流。
- 消费者API:支持应用程序订阅Topic和处理Record流。
- Stream API:将输入流转换为输出流,并产生结果。
- Connector API:执行可重用的生产者和消费者API,可将Topic链接到现有应用程序。
相关术语
- Topic 用来对消息进行分类,每个进入到Kafka的信息都会被放到一个Topic下
- Broker 用来实现数据存储的主机服务器
- Partition 每个Topic中的消息会被分为若干个Partition,以提高消息的处理效率
- Producer 消息的生产者
- Consumer 消息的消费者
- Consumer Group 消息的消费群组
Kafka的性能
由于其广泛集成到企业级基础设施中,监测Kafka在规模运行中的性能成为一个日益重要的问题。监测端到端性能,要求跟踪所有指标,包括Broker、消费者和生产者。除此之外还要监测ZooKeeper,Kafka用它来协调各个消费者。[8][9]目前有一些监测平台可以追蹤Kafka的性能,有开源的,如领英的Burrow;也有付费的,如Datadog。除了这些平台之外,收集Kafka的数据也可以使用工具来进行,这些工具一般需要Java,包括JConsole。[10]
Kafka文件格式
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex 00000000000000782248.snapshot leader-epoch-checkpoint
使用Kafka的企业
下面的列表是曾经或正在使用Kafka的知名企业:
参见
- Apache ActiveMQ
- Apache Flink
- Qpid
- Samza
- Apache Spark
- 数据发布服务
- 企业集成模式
- 企业消息系统
- 事件流式处理
- 事件驱动SOA
- 面向消息的中间件
- 面向服务的架构
- StormMQ
参考资料
- . [2014-04-09]. (原始内容存档于2020-08-16).
- [开源的Kafka,LinkedIn的分布式消息队列]. [2016-10-27]. (原始内容存档于2021-01-11).
- . 2024年2月26日 [2024年3月19日].
- [监控Kafka性能数据]. Datadog官方博客. [2016-05-23]. (原始内容存档于2020-11-08) (英语).
- [The Log: What every software engineer should know about real-time data's unifying abstraction]. 领英官方博客. [2014-05-05]. (原始内容存档于2014-03-17) (英语).
- Primack, Dan. [领英工程师推迟发布Kafka启动Confluent]. [2015-02-10]. (原始内容存档于2020-10-22) (英语).
- [作家卡夫卡和Apache Kafka那个分布式消息系统之间有什么关系?]. [2017-06-12] (英语).
- [监测Kafka性能指标]. 2016-04-06 [2016-10-05]. (原始内容存档于2020-11-08) (英语).
- Mouzakitis, Evan. [监测Kafka性能指标]. 2016-04-06 [2016-10-05]. (原始内容存档于2020-11-08) (英语).
- [收集Kafka性能指标-Datadog]. 2016-04-06 [2016-10-05]. (原始内容存档于2020-11-27) (英语).
- [更多数据,更多数据]. [2017-12-22]. (原始内容存档于2018-10-21) (英语).
- [Kafka在Ebay通信传递管道中的用途]. [2017-12-22]. (原始内容存档于2019-02-16) (英语).
- Doyung Yoon. [S2Graph:基于HBase的大规模图形数据库]. [2017-12-22]. (原始内容存档于2016-03-09) (英语).
- Cheolsoo Park and Ashwin Shankar. [Netflix:在Pb级规模集成Spark]. [2017-12-22]. (原始内容存档于2016-03-04) (英语).
- Shibi Sudhakaran of PayPal. [PayPal:创建中心数据骨干:Couchbase Server到Kafka到Hadoop和Back(在Couchbase Connect 2015上的讲话)]. Couchbase. [2016-02-03]. (原始内容存档于2016-09-17) (英语).
- Josh Baer. [Apache如何驱动Spotify的音乐推荐]. [2017-12-22]. (原始内容存档于2016-03-09) (英语).
- [从Kafka到Redshift的流式消息接近于实时]. Yelp. [2017-07-19]. (原始内容存档于2017-06-03) (英语).
- Boerge Svingen. [在纽约时报使用Kafka进行出版]. [2017-09-19]. (原始内容存档于2017-09-17) (英语).
- [OpenSOC:一份公开的安全承诺]. 思科博客. [2016-02-03]. (原始内容存档于2016-03-09) (英语).
- [Kafka用于项目设置]. medium.com. [2017-06-12]. (原始内容存档于2019-05-03) (英语).
- [优步的流式处理]. InfoQ. [2015-12-06]. (原始内容存档于2015-12-05) (英语).
外部链接
- Apache Kafka网站(页面存档备份,存于)(英文)
- 项目设计讨论(页面存档备份,存于)(英文)
- Github镜像 (页面存档备份,存于)
- Morten Kjetland对Apache Kafka的介绍(页面存档备份,存于)(英文)
- Quora上与RabbitMQ的对比(英文)
- Kafka开发者邮件列表中与RabbitMQ的对比(页面存档备份,存于)(英文)
- Stackoverflow上与RabbitMQ和ZeroMQ的对比(页面存档备份,存于)(英文)
- Apache Kafka中的集群内部响应(页面存档备份,存于)(英文)
- Kafka用户邮件列表讨论(英文)